
Artificial intelligence is growing fast, especially in the era of large language models. Big tech companies are spending a lot on improving AI models that understand and create human-like language.
According to a Bloomberg report, Generative AI is supposed to be worth $1.3 trillion by 2032. In the same context, the Meta LLama 3 model is a big deal for open-source Large Language Models.
But why is it necessary these days? Keep reading further to find out what LLama 3 is, how it works, what its main features are, and what sets it apart from other top models.
Here, we will show you how easy it is to run it on Hyperstack with just a few clicks. You will also explore how Meta’s open-source approach could shape the future of AI.
About Meta LLaMA 3

LLaMA 3, which stands for Large Language Model Meta AI 3, is the latest open-source large language model development service created by Meta. It’s been trained on a huge amount of text data, which helps it understand language really well.
This makes it great for tasks like writing, translating languages, and giving informative answers to questions. The model will be available on various platforms including AWS, Google Cloud, and Microsoft Azure, among others.
Meta LLaMA 3 model aims to make advanced language AI accessible to everyone. Its release puts Meta among the top AI and machine learning development company assistants globally, raising the bar for what these systems can do.
The model emphasizes innovation, scalability, and simplicity, boasting several upgrades from its predecessor, LLama 2. This involves the following improvements:
- Better tokenizer for efficiency
- Use of grouped query attention (GQA) to make inferences faster
- Ability to handle longer sequences of up to 8,192 tokens
We use Meta LLama 3 to improve automation, efficiency, and decision-making.
What’s new in Meta LLama 3? This model has been trained extensively on a massive scale, using over 15 trillion tokens of publicly accessible data. This data covers many different areas, such as code, historical information, and different languages.
By combining this diverse and extensive training dataset with Meta’s advancements in pre-training and fine-tuning, LLaMA 3 has become a top-performing model. It excels across various industry tests and real-world situations.
Key Features of the LLAMA 3 Model

Explore the cutting-edge features of the Meta LLaMA 3 model, revolutionizing the landscape of large language models. Look into its advancements and capabilities below.
- LLaMA 3 keeps its decoder-only transformer design but with big improvements. One key enhancement is its tokenizer, which now supports 128,000 tokens, making it much better at encoding language efficiently.
- Integrated into 8 billion and 70 billion parameter models, this improves how efficiently the models process information, making their processing focused and effective.
- LLaMA 3 performs better than its older versions and competitors in different tests, especially in tasks like MMLU and HumanEval, where it stands out.
- Meta LLaMA 3 model has been trained on a dataset of over 15 trillion tokens, which is seven times bigger than the dataset used for LLaMA 2. This dataset includes a wide range of languages and linguistic styles, incorporating data from over 30 languages.
- Careful scaling laws are used to balance the mix of data and computational resources, ensuring that LLaMA 3 performs well across different uses. Compared to LLaMA 2, its training process is now three times more efficient.
- After training, LLaMA 3 undergoes an improved post-training phase. This phase includes supervised fine-tuning, rejection sampling, and policy optimization, all of which aim to enhance the model’s quality and decision-making abilities.
- LLaMA 3 is accessible on major platforms and offers improved efficiency and safety features in its tokenizer. This empowers developers to customize applications and ensure responsible AI deployment.
Hence, the Meta LLama 3 model sets a new standard for accessibility and performance in language AI. To enhance tokenizer efficiency and deploy robust safety features, you may hire top LLM developers who can confidently tailor applications for responsible deployment.
Also Read: Meta Makes Messaging Smarter: Meta AI Integration Rolls Out On WhatsApp
Top Capabilities of LLama 3
Meta has developed its latest open AI model, LLaMA 3, to rival the best proprietary models available today.
According to Meta, addressing developer feedback to boost the overall efficiency of LLaMA 3 while prioritizing responsible use and deployment of Large Language Models (LLMs) was crucial.
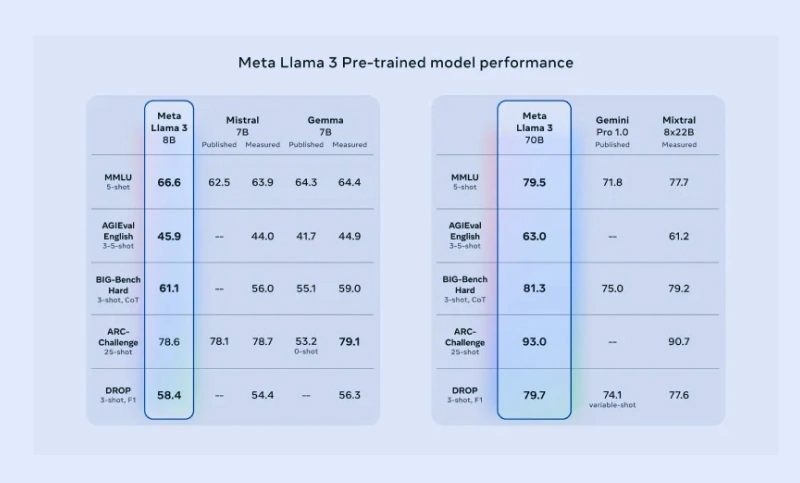
Compared to its predecessor, LLaMA 2, LLaMA 3 excels in reasoning abilities, code generation, and effectively follows human instructions. It also surpasses other open models on benchmarks like ARC, DROP, and MMLU, all thanks to the revolutionary capabilities of LLaMA 3.
Let ValueCoders optimize Meta LLaMA 3 for faster inferences and smarter solutions that save time and costs.
State-of-the-Art Performance
The new 8B and 70B parameter Meta LLaMA 3 models represent a significant advancement over LLaMA 2, setting a new standard for Large Language Models for enterprises at these scales.
Thanks to enhancements in both pretraining and post-training phases, these pre-trained and instruction-fine-tuned models are currently the top performers at their respective scales.
The improvements in post-training procedures notably reduced false refusal rates, enhanced alignment, and diversified model responses.
Additionally, notable enhancements in capabilities such as reasoning, code generation, and instruction following make LLaMA 3 more adaptable and effective.
During the development of the Meta LLaMA 3 model, the team focused on assessing model performance on both standard benchmarks and real-world scenarios.
As part of this effort, a new high-quality human evaluation set was created, consisting of 1,800 prompts covering 12 key AI use cases. These include tasks like asking for advice, brainstorming, coding, creative writing, reasoning, and summarization.
To ensure fairness, even the modeling teams couldn’t access this evaluation set, preventing accidental bias. The aggregated results of human evaluations across these categories and prompts are displayed in the chart below, comparing LLaMA 3 against Claude Sonnet, Mistral Medium, and GPT-3.5.

Based on this evaluation set, rankings by human annotators underscore the impressive performance of our 70B instruction-following model compared to similarly sized competing models in real-world scenarios.
Additionally, our pre-trained model sets a new benchmark for Large Language Models (LLMs) at these scales.
In the development of Meta LLaMA 3 model, a commitment to innovation, scalability, and simplicity was paramount. This guiding principle influenced every aspect of the project, with a particular emphasis on four essential elements: the model’s architecture, the data used for pretraining, the process of scaling up pretraining and fine-tuning through instruction.
Optimized Model Architecture
Why LLaMA matters? Following their design philosophy, the team behind LLaMA 3 chose a standard decoder-only transformer architecture. Compared to its predecessor, LLaMA 2, several key enhancements were implemented.
LLaMA 3 features a tokenizer with a vocabulary of 128K tokens, improving language encoding efficiency and consequently enhancing model performance.
Additionally, to boost the inference efficiency of Meta LLaMA 3 models, grouped query attention (GQA) was adopted across both the 8B and 70B sizes. These models were trained on sequences of 8,192 tokens, with a masking mechanism ensuring that self-attention does not extend beyond document boundaries.
Extensive High-Quality Training Data
Ensuring the best language model requires a meticulously curated, extensive training dataset. Adhering to their design principles, the team behind LLaMA 3 prioritized investing in pretraining data.
LLaMA 3 underwent pretraining on a dataset containing over 15 trillion tokens sourced entirely from publicly accessible platforms. This dataset is notably seven times larger than that utilized for LLaMA 2, with a fourfold increase in code content.
In anticipation of future multilingual applications, more than 5% of LLaMA 3’s pretraining dataset comprises high-quality non-English data spanning over 30 languages. However, it’s acknowledged that performance in these languages may not reach the same level as in English.
To guarantee that LLaMA 3 is trained on top-notch data, a set of data-filtering pipelines was devised. These pipelines incorporate heuristic filters, NSFW filters, semantic deduplication methods, and text classifiers to assess data quality.
Interestingly, earlier versions of LLaMA demonstrated proficiency in identifying high-quality data. As a result, LLaMA 2 was utilized to generate training data for the text-quality classifiers powering LLaMA 3.
Extensive experiments were conducted to determine the most effective methods of combining data from various sources in the ultimate pretraining dataset.
These experiments helped identify a data blend that guarantees optimal performance for the Meta LLaMA 3 model across various applications, including trivia questions, STEM topics, coding, historical knowledge, and more.
Our experts at ValueCoders can help you explore Meta’s LLama 3's full potential to improve accuracy and reliability.
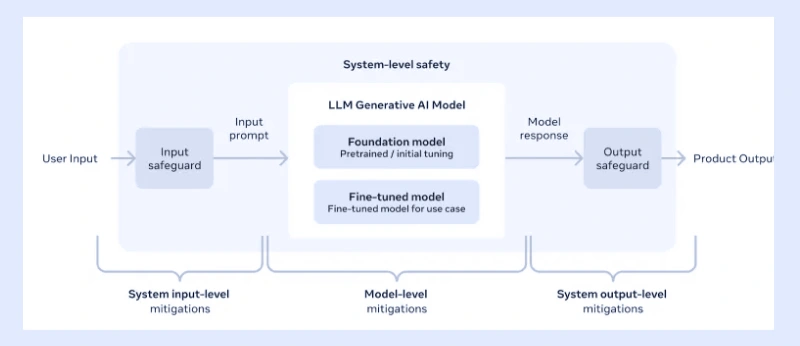
Responsible AI Approach
Meta has embraced a comprehensive approach to responsible AI, empowering developers to maintain control over the usage of Meta LLaMA 3 models.
This involves iterative fine-tuning of instructions alongside rigorous red-teaming and adversarial testing to prioritize the development of safe and robust models.
Additionally, new tools such as LLaMA Guard 2, utilizing the MLCommons taxonomy, CyberSecEval 2 for evaluating code security, and Code Shield for filtering insecure generated code, further support responsible deployment.
An updated Responsible Use Guide offers developers a comprehensive framework to adhere to ethical practices.
Streamlined for Effective Deployment
Apart from enhancing the models themselves, significant effort was directed toward optimizing LLaMA 3 for efficient deployment on a large scale.
A revamped tokenizer improves token efficiency by up to 15% compared to LLaMA 2. The integration of GQA ensures that the 8B model maintains inference parity with the previous 7B model.
LLaMA 3 models will be accessible across all major cloud providers, model hosts, and other platforms. Extensive open-source code for tasks such as fine-tuning, evaluation, and deployment is also available.
Also Read: AI-Powered Future: Revolutionizing Businesses With Tools Like ChatGPT
LLaMA vs. GPT, Gemini, and Other AI Models
When comparing LLaMA with other AI models for apps like GPT and Gemini, several factors come into play.

This table provides a brief overview of the distinguishing features and strengths of LLaMA, GPT, Gemini, and other AI models, aiding in understanding their respective capabilities and applications.
Meta LLaMA 3 models stand out for their innovative features, extensive training on diverse datasets, and optimized architecture for efficient performance.
While when you hire GPT experts and Gemini experts, they have their strengths, LLaMA’s focus on scalability, versatility, and responsible AI deployment sets it apart in the competitive landscape of language models.
Also read: DeepSeek Vs ChatGPT Vs Google Gemini Vs GitHub Copilot : A Comprehensive Comparison
Future Developments in LLama 3
The release of the LLaMA 3 8B and 70B models signals the start of Meta’s future plans for LLaMA 3, with many more developments anticipated in the pipeline.
The team is currently training models with over 400 billion parameters, and there is considerable excitement about their progress.
In the upcoming months, Meta plans to release several models with enhanced features, such as multimodality, multilingual conversation abilities, increased context window, and improved overall capabilities.
Additionally, a comprehensive research paper detailing the training of the Meta LLaMA 3 model will be published upon completion.
As the largest LLM models continue their training, hire LLM engineers as they offer a sneak peek into their progress with some snapshots.
It’s important to note that this data is derived from an early checkpoint of LLaMA 3 and does not reflect the capabilities available in the currently released models.

Meta is dedicated to fostering the ongoing growth and advancement of an open AI ecosystem for the responsible release of its models. They firmly believe that openness fosters the development of superior, safer products, accelerates innovation, and promotes a healthier market overall. This approach benefits both Meta and society as a whole.
With Meta LLaMA 3 model, Meta is prioritizing a community-centered strategy. As of today, these models are accessible on various leading cloud, hosting, and hardware platforms, with more platforms set to follow in the future.
ValueCoders’ team is ready to implement the advanced capabilities of LLaMA 3 to boost your business intelligence.
Concluding Thoughts!
Introducing the Meta LLama 3 model carries substantial implications for both AI users and developers. Having access to such a language model opens the door to a plethora of new AI-driven applications and services spanning various fields.
Meta’s efforts to offer tools, guidance, and infrastructure support for LLama 3 will play a crucial role. Meta is rolling out new trust and safety tools, such as updated LLama Guard 2 and CyberSec Eval 2 features.
Additionally, they are introducing Code Shield, a safeguard during inference that filters out insecure code generated by large language models (LLMs).
LLama 3 was developed alongside torch tune, a new PyTorch-based library aimed at simplifying the creation, fine-tuning, and experimentation with LLMs. Torchtune provides memory-efficient and customizable training methods, all written in PyTorch.
The library seamlessly integrates with well-known platforms like Hugging Face, Weights & Biases, and EleutherAI. Additionally, it supports Executorch, allowing a generative AI development company for efficient inference on a range of mobile and edge devices.
Ready to utilize the power of AI for your projects? Partner with ValueCoders, a leading AI development company, and unlock endless possibilities. Let’s innovate together!





